In our previous post on data scraping, we examined how to filter NBA.com to a specific game date, and extract stats for that game date. That was a great first step, and we’re going to keep building on it. In this post, we’re going to walk you through how to loop through multiple game dates, and build your own personal database of NBA stats! Anyone who wants to become a serious sports bettor needs to dig deep into the data themselves.
The first step in the process of building your own NBA sports betting dataset is figuring out what calendar dates were actually valid game dates for a particular NBA season. This may seem trivial at first, but once you start considering the Covid delayed season, the new addition of play-in games, and the actual playoffs, it can actually get pretty confusing trying to figure out which dates correspond to which basketball games, and which basketball games correspond to which season types (regular season, play-in, bubble, playoffs).
There aren’t any additional prerequisites for the post, so as long as you were successfully able to get through the previous post, you should be fine here too!
The site we’re going to use to extract the game dates is www.BasketballReference.com , and the Python library we’re going to use to scrape the website will again be selenium.
We’re going to write a function that takes in a season in the form of ‘2020-21’ and passes it as a URL parameter which contains all of the game dates for that corresponding NBA season. Then, we’re going to use the find_elements_by_xpath built-in Selenium method to find all the “href” tags on the page. Each of these “href” tags contain a link for each month of the basketball season. Below is the code for just this part:
# Get season in the correct format and get the correct url for that season
season_formatted = '20'+season.split('-')[1]
driver.get(f'https://www.basketball-reference.com/leagues/NBA_{season_formatted}_games.html')
elems = pd.Series([val.get_attribute("href") for val in driver.find_elements_by_xpath("//a[@href]")])
month_links = list(elems[elems.str.contains(f'https://www.basketball-reference.com/leagues/NBA_{season_formatted}_games-')].values)Next, we’re going to loop over month_links, send our driver to that url, and use the built-in Pandas read_html function to extract the contents of the page in a tabular format.
# Loop through links and get game_dates lists
for link in month_links:
driver.get(link)
time.sleep(2)
local_df = pd.read_html(driver.page_source)[0]
full_df = pd.concat([full_df,local_df])Lastly, we do some basic string formatting to extract the date, convert the date column to a Pandas datetime object, and extract the list of unique dates! That’s it! You now have a list of all game dates in a particular NBA season. Here’s the entire function below for your convenience.
def get_game_dates(season):
# Get season in the correct format and get the correct url for that season
season_formatted = '20'+season.split('-')[1]
driver.get(f'https://www.basketball-reference.com/leagues/NBA_{season_formatted}_games.html')
elems = pd.Series([val.get_attribute("href") for val in driver.find_elements_by_xpath("//a[@href]")])
month_links = list(elems[elems.str.contains(f'https://www.basketball-reference.com/leagues/NBA_{season_formatted}_games-')].values)
full_df = pd.DataFrame()
# Loop through links and get game_dates lists
for link in month_links:
driver.get(link)
time.sleep(2)
local_df = pd.read_html(driver.page_source)[0]
full_df = pd.concat([full_df,local_df])
full_df['GAME_DATE'] = pd.to_datetime(full_df['Date'].apply(lambda x: x[5:]))
full_df['GAME_DATE'] = full_df['GAME_DATE'].astype(str).apply(lambda : x[:10])
full_df = full_df[full_df['Date']!='Date']
game_dates = list(full_df['GAME_DATE'].unique())
return game_datesBut wait – you’re probably wondering “What on earth am I supposed to do with these dates?”
I’m glad you asked. If you go back to our first blog post, you’ll see the get_players_leader function takes in a game_date. Here it is again if you missed our previous post.
def get_players_leader(game_date):
year = str(game_date)[:4]
month = str(game_date)[5:7]
day = str(game_date)[8:10]
url = f'https://www.nba.com/stats/leaders/?SeasonType=Regular%20Season&DateTo={month}%2F{day}%2F{year}&DateFrom={month}%2F{day}%2F{year}'
driver.get(url)
time.sleep(2)
#Recognizing cookies in the page and accepting so Selenium can find the table
cookie_list = driver.find_elements_by_id('onetrust-accept-btn-handler')
if len(cookie_list)>0:
cookie_list[0].click()
time.sleep(2)
select_list = driver.find_elements_by_xpath('/html/body/main/div/div/div[2]/div/div/nba-stat-table/div[1]/div/div/select')
#Showing all players available on the filter
if (len(select_list)>0):
select_field = Select(select_list[0])
select_field.select_by_visible_text('All')
time.sleep(2)
#Getting and returning dataframe
stat_df = pd.read_html(driver.page_source)[0]
stat_df['GAME_DATE'] = game_date
return stat_df
game_dates = get_game_dates('2020-21')All you have to do now is loop through the game_dates we extracted above, and pass them in as an argument to the get_players_leader function. The code for it is listed below. It may take some time for it to get through every game date, but rest assured, by the end of this for loop you’ll have an entire season’s worth of NBA data for you to analyze.
# You can use tqdm so you can know how much time left for the loop to end
from tqdm import tqdm
# Looping through all the dates from the list and putting the dataframe together
full_df = pd.DataFrame()
for date in tqdm(game_dates):
local_df = get_players_leader(date)
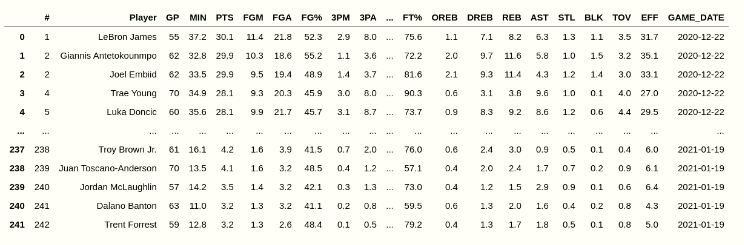
full_df = pd.concat([full_df,local_df])The resulting dataframe should look something like this: